[2385 vues] 2022-01-04 Emmanuel Orchanian
Concept
Le concept est de coder pas à pas une fonction en langage PHP.
À qui c'est destiné
Tout le monde, pas forcément les codeurs, et pas forcément les codeurs PHP.
En effet, je prête une attention particulière à la méthodologie et à l'épanouissement.
Bonne lecture !
Qu'est ce que l'écriture en kébab ?
Écrire en kébab c'est tout mettre en minuscule et remplacer les espaces par des traits d'union.il-faut-ecrire-comme-ca
La phrase
Œuvre n°12 des garçons : "Le Noël de Léon" classe des 6ème2 de l'IND (Institution Notre-Dame).devient
oeuvre-n-12-des-garcons-le-noel-de-leon-classe-des-6eme2-de-l-ind-institution-notre-dame
Règles de base
- que des lettres de l'alphabet latin (pas d'accent, de cédilles, de ligatures, de ponctuations ou d'autres caractères spéciaux)
- que des chiffres arabes
- le trait d'union pour séparer
Règles subtiles
- on ne peux pas avoir plusieurs trait d'union consécutifs
---- - on ne peux pas commencer ou finir par un trait d'union
- lettres en minuscule
Objectif
Avoir une fonction PHP qui transforme un texte normal en texte kébabé (je viens d'inventer un mot ! 🍖😀)
Voici ce que je vous ai préparé pour l'étude d'aujourd'hui
<?php
function kebab(string $s){
$s = trim(html_entity_decode($s));//ligne rajoutée à la fin
// caratères à remplacer par d'autres caratères
// voyelles
$s = str_ireplace(mb_str_split('áâàåãä'), 'a',$s);
$s = str_ireplace(mb_str_split('æ'), 'ae',$s);
$s = str_ireplace(mb_str_split('éêèë'), 'e',$s);
$s = str_ireplace(mb_str_split('íîìï'), 'i',$s);
$s = str_ireplace(mb_str_split('óôòøõö'), 'o',$s);
$s = str_ireplace(mb_str_split('œ'), 'oe',$s);
$s = str_ireplace(mb_str_split('ùûüúûùü'), 'u',$s);
$s = str_ireplace(mb_str_split('ýÿ'), 'y',$s);
// consonnes
$s = str_ireplace(mb_str_split('ç¢'), 'c',$s);
$s = str_ireplace(mb_str_split('Ð'), 'd',$s);
$s = str_ireplace(mb_str_split('ñ'), 'n',$s);
$s = str_ireplace(mb_str_split('š'), 's',$s);
$s = str_ireplace(mb_str_split('€'), 'e',$s);
// autres
$s = str_ireplace(mb_str_split('ƒ'), 'f',$s);
$s = str_ireplace(mb_str_split('ß'), 'ss',$s);
$s = str_ireplace(mb_str_split('$'), 'dol',$s);
$s = str_ireplace(mb_str_split('@'), 'at',$s);
$s = str_ireplace(mb_str_split('²'), '2',$s);
$s = str_ireplace(mb_str_split('³'), '3',$s);
// caractères à remplacer par un -
$s = str_ireplace(mb_str_split('&~"`°=¨£¤%µ,;:§_\''), '-',$s);
$s = str_ireplace(mb_str_split('^\\|.{}[]()?#!+*'), '-',$s); // regex sauf dollar // (laisser) }
$s = str_ireplace(mb_str_split(' '), '-',$s);//espace
// on enleve tous les autres caractères
// on ne trie plus que les caracteres autorisés en kebab, pour enlever les émoticônes qui font plusieurs bytes (certains se mélangent) ❤ est plus court que 🔁
$chara_kebab = '-0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' ;
$arr_chara_kebab = str_split($chara_kebab);
$s_tmp = '';
foreach (mb_str_split($s) as $value) if( in_array($value, $arr_chara_kebab)) $s_tmp .= $value ;
$s = $s_tmp;
//enlever les - au debut et a la fin
$s = trim($s,'-');
// on enlève les tirets en doublon
while(strpos($s, '--')!==false) $s = str_ireplace('--', '-',$s); // plusieurs tirets
return $s;
}
Le codage
À présent, kébabons. 😁
<?phpJe commence pas ouvrir ma balise PHP bien sûr (pour les débutants, sachez qu'il faut obligatoirement utiliser un serveur, par exemple WAMP mais c'est un autre sujet).
function kebab(string $s)- le mot-clé
functionsignifie "crée la fonction" kebab= le nom de la fonction, je décide d'un nom simple au lieu de "kebab_case" car je sais que je n'aurai pas de confusion à la base avec le mot kébab dans le code...(...)entre parenthèses je met ce que je "donne à manger" à la fonction, c'est-à-dire les paramètresstringen PHP le mot clef désigné ici transformera automatiquement le type reçu en string, c'est-à-dire en chaîne de caractère, ou plus simplement dit, en texte...
Par exemple, si je lui demande d'écrire nombre 315, il prendra en compte le texte "315"$sje décide de donner un nom simple à la variable créée ici, "s" signifie string, donc texte en français.
Ça sera notre héros ! 😀
function kebab(string $s){
// ici j'écrirai toutes les instructions
}
On met entre accolades { } tout ce que fera notre ami la fonction "kebab"
À partir d'ici je mettrai ce que j'écrirai à l'intérieur de ces accolades.
$s = mb_strtolower($s);En français : dollar s devient égal à dollar s en minuscule.
En d'autre terme, "met tout en minuscule". 🐜
Je commence par tout mettre en minuscule, ainsi je n'aurai pas à dire par exemple que À et à se transforment en a, ça me fait économiser la moitié des remplacements.
De toute manière j'aurai tout en minuscule à la fin.
En PHP le point-virgule; à la fin permet de ponctuer une instruction.
strtolower se lit "String to lower" et se traduit par "texte mis en minuscule"
Il existe la fonction php strtolower(), pourquoi ne l'ai-je pas utilisé ?
La différence entre strtolower et mb_strtolower est que le premier ne fonctionne que sur les lettres "classiques" de nos écritures occidentales, alors que le second agit sur les écritures grecques, cyrilliques (russe) etc.
Puisque je ne sais pas trop à quoi m'attendre, je préfère avoir un code méfiant.
Puis je conseille d'utiliser mb_strtolower car il englobe strtolower de toute façon.
Trois objectifs
- Remplacer certains caractères par des lettres ou des chiffres.
Par exempleécoledevientecole - Remplacer par un trait d'union.
Par exemple avec les apostrophes :l'oiseaudeviendraitl-oiseau - Supprimer certains caractères : par exemple les émoticônes 😏🍕🛴
Remplacement de caractères par des lettres ou des chiffres
$s = str_ireplace(mb_str_split('áâàåãä'), 'a',$s);a accentués par un a sans accent dans dollar s ). Ou en d'autre termes enlève moi les accents sur les
a
str_ireplaceest une fonction qui indique qu'on va faire un remplacement dans un texte.strsignifie "string", texte en anglais, et la lettreisignifie qu'on est insensible à la casse, c'est-à-dire qu'on s'en fiche si la lettre est minuscule ou majuscule.
Mais alors, pourquoi insister sur les majuscules alors qu'on les avait enlevé un peu plus haut ? Pour être sûr tout simplement, je ne sais pas ce que j'ai comme phrase d'entrée, je peux avoir quelque chose écrit avec des émoticônes, des choses bizarres, je préfère insister en marquant le coup.- Si vous remarquez, la fonction
str_ireplaceest composé de trois parties dans ses parenthèses :str_ireplace( mb_str_split('áâàåãä') ,'a' , $s )
Cela signifie qu'on remplace [partie 1] par [partie 2] à l'intérieur de [partie 3].
Ici on remplacemb_str_split('áâàåãä')par la lettre "a" dans notre texte dollar s. - Étudions plus en détails
mb_str_split('áâàåãä'): tout à l'heure j'écrivais questr_ireplacetransforme un tableau, en faitmb_str_splitpermet de transformer le texte "áâàåãä" en tableau['á', 'â', 'à', 'å', 'ã', 'ä'] - J'ai voulu coupler
str_ireplaceetmb_str_splitpour éviter d'écrirestr_ireplace(['á', 'â', 'à', 'å', 'ã', 'ä'], 'a',$s)qui est complètement indigeste selon-moi, mais je vais argumenter :
J'ai le choix entre utiliser deux fonctions et écrire 'áâàåãä', ou alors utiliser une seule fonction et écrire le tableau ['á', 'â', 'à', 'å', 'ã', 'ä'].
Lequel choisir ?$s = str_ireplace(mb_str_split('áâàåãä'), 'a',$s); // fait la même chose que : $s = str_ireplace(['á', 'â', 'à', 'å', 'ã', 'ä'], 'a',$s);
Si je facilite un côté, ça complexifie d'un autre côté, alors je dois faire un choix : quelle est la meilleure solution ?
Voici, je recommande toujours de choisir la solution la plus maintenable. Ici, imaginons que je veuille ajouter une nouvelle lettre à remplacer que je vais appelerX,- avec
'áâàåãä'j'ai juste un caractère à écrire'áâàåãäX' - avec
['á', 'â', 'à', 'å', 'ã', 'ä']je dois rajouter un séparateur (la virgule), ouvrir des guillemets, ça donnerai
['á', 'â', 'à', 'å', 'ã', 'ä', 'X']
J'augmente ainsi la probabilité de faire des fautes de frappe (dans le premier cas j'ai une seule lettre à écrire, dans le second j'en ai au moins 4...) ce qui est bien sûr à éviter.
- avec
Je procède ainsi de même pour d'autres caractères :
// voyelles
$s = str_ireplace(mb_str_split('áâàåãä'), 'a',$s);
$s = str_ireplace(mb_str_split('æ'), 'ae',$s);
$s = str_ireplace(mb_str_split('éêèë'), 'e',$s);
$s = str_ireplace(mb_str_split('íîìï'), 'i',$s);
$s = str_ireplace(mb_str_split('óôòøõö'), 'o',$s);
$s = str_ireplace(mb_str_split('œ'), 'oe',$s);
$s = str_ireplace(mb_str_split('ùûüúûùü'), 'u',$s);
$s = str_ireplace(mb_str_split('ýÿ'), 'y',$s);
// consonnes
$s = str_ireplace(mb_str_split('ç¢'), 'c',$s);
$s = str_ireplace(mb_str_split('Ð'), 'd',$s);
$s = str_ireplace(mb_str_split('ñ'), 'n',$s);
$s = str_ireplace(mb_str_split('š'), 's',$s);
$s = str_ireplace(mb_str_split('€'), 'e',$s);
// autres
$s = str_ireplace(mb_str_split('ƒ'), 'f',$s);
$s = str_ireplace(mb_str_split('ß'), 'ss',$s);
$s = str_ireplace(mb_str_split('$'), 'dol',$s);
$s = str_ireplace(mb_str_split('@'), 'at',$s);
$s = str_ireplace(mb_str_split('²'), '2',$s);
$s = str_ireplace(mb_str_split('³'), '3',$s);
Remarquez que j'ai fait des choix très subjectifs qui peuvent varier en fonction de chaque développeur, par exemple de remplacer le @ par un at, certains auraient préférés a
Quelques caractères sont discutables, par exemple l'eszett allemand "ß" deviens "ss". Il faut connaître, personnellement j'avais choisi espagnol 3ème langue au lycée, l'allemand je n'y connais rien, et c'est à cause de ça qu'une fois entré à l'armée on nous a demandé "qui a fait espagnol 3ème langue ?" - "Moi ! Moi !" - "Bon ben tu passera le balai !" 🇪🇸
(je me permet de mettre un peu d'humour de toute façon je ne sais même pas si des êtres humains sont toujours en train de lire là où j'en suis...)
J'ai également très joliment rangé mon code en catégories (voyelles, consonnes, autres) 🦚🦋🌸🌺🌼 et j'ai placé des paragraphes titrés par un petit commentaire, ça permet d'avoir un code plus lisible.
Caractères à remplacer par un trait d'union
$s = str_ireplace(mb_str_split('&~"`°=¨£¤%µ,;:§_\''), '-',$s);
$s = str_ireplace(mb_str_split('^\\|.{}[]()?#!+*'), '-',$s);
// regex sauf dollar // (laisser) }
$s = str_ireplace(mb_str_split(' '), '-',$s);//espace
Je décide de couper le code en trois paquets.
- pour des signes quelconques que je verrai bien être remplacés par un trait d'union
- pour d'autres signes, particulièrement ceux qui servent dans les REGEX (les expressions régulières), parce que je code est la reprise du même code que j'avais fait en JavaScript, et dans le JavaScript, avant, on avait forcément besoin des REGEX pour effectuer des remplacements.
Puisque ça ne me dérange pas de séparer en deux lignes, alors je préfère le faire pour mieux ranger les textes. D'autant plus que les REGEX sont souvent utiles, j'aurai ça sous le coude. - Et en dernier, l'espace.
Quelques précisions
- J'ai voulu distinguer l'espace pour deux raisons : c'est le séparateur naturel des mots en français, puis ça permet de mieux le voir. Notez que j'ai commenté
// espacepour ne pas embrouiller d'autres développeurs. Souvent, il est préférable de mettre en valeur l'espace quand il est utilisé formellement dans un code, sinon il ne se voit pas. &~"`°=¨£¤%µ,;:§_\'
Constatez le\'à la fin, on appelle ça l'échappement, ça veut dire que j'indique au code que l'apostrophe'"s'échappe" du texte, normalement il a pour rôle d'indiquer qu'on arrête le texte en PHP (car en informatique les apostrophes peuvent s'utiliser de la même manière que les guillemets), mais ici je veux que mon signe apostrophe soit réellement dans le texte. Donc je met un\devant pour préciser que mon apostrophe s'échappe et qu'il ne referme pas le texte.\\puisque le signe antislash\sert à s'échapper, alors il faut préciser quand on veux vraiment écrire le signe\, alors on l'échappe tout simplement, ainsi le\\équivaut à un simple\- Remarquez la fin du commentaire
(laisser) }dans
j'avais un problème d'indentation dans mon éditeur (en informatique on décale le texte par rapport à la marge de gauche car la distance a une signification particulière). Je me suis rendu compte que si je mettais une accolade fermante$s = str_ireplace(mb_str_split('^\\|.{}[]()?#!+*'), '-',$s); // regex sauf dollar // (laisser) }}en commentaire, ça résolvait ce problème.
Parfois votre éditeur de code peux créer une indentations avec les( [ {à l'intérieur des textes, ce qui normalement est faux. Pour contrer ça, on peux écrire respectivement des) ] }en commentaire dans la même ligne.
Attention de ne pas trop en mettre sinon on sautera de l'autre côté du cheval en faisant une indentation anormale vers la gauche cette fois-ci...
Je précise que ce problème arrive rarement mais il a la particularité d'être énervant. 😡
On enlève tous les autres caractères
Pour rappel, il faut que chaque lettre de ma phrase soit une lettre latine, un chiffre arabe ou un trait d'union.
Pour filtrer les caractères à supprimer, je ne vais pas m'amuser à faire une liste des millions d'émoticônes 😏🍕🛴 qui existent et autres signes que je ne connais pas comme අ ආ ඇ ඈ ඉ ඊ උ ඌ ඍ ඎ ඏ voir lien Wikipédia
J'ai deux manière pour nettoyer un texte :
- soit on utilise un texte sale et on enlève les saletés de dedans
- soit on crée un texte vide et on lui ajoute un par un les éléments propres issus du texte sale en filtrant les éléments "toi tu passes, toi tu ne passes pas".
Préparation du filtrage
$chara_kebab = '-0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' ;
$arr_chara_kebab = str_split($chara_kebab);
Ici, je crée une variable "chara_kebab" qui contient un texte qui contient tous les caractères autorisés en kébab. J'ai fait exprès de mettre le trait d'union en premier pour ne pas l'oublier, si je le met à la fin je risque de ne pas le voir...
La ligne suivante indique que je crée un tableau, "arr_chara_kebab", qui contient chacune de ces lettres.
$s_tmp = '';
foreach (mb_str_split($s) as $value) {
if( in_array($value, $arr_chara_kebab)) {
$s_tmp .= $value ;
}
}
$s = $s_tmp;
Étude du code :
Avant-pendant-après
J'appelle ça le "AVANT-PENDANT-APRÈS"
- AVANT la boucle, je crée un conteneur vide (ça peux être un texte ou un tableau)
PENDANT la boucle, je rempli un par un le conteneur- APRÈS la boucle, mon conteneur est entièrement rempli, je peux l'utiliser.
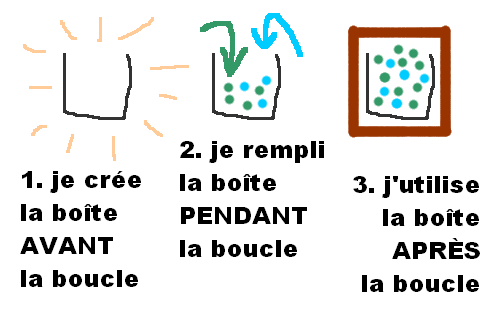
AVANT
$s_tmp = '';En français : je crée la variable qui s'appelle "dollar s underscore tmp" qui deviens égal à un texte vide. (tmp est l'abréviation de temporel, c'est-à-dire quelque chose qui ne va pas durer longtemps et qui n'est utile que pour quelques petites lignes.)
PENDANT
foreach (mb_str_split($s) as $value)En français : for each = "pour chaque" lettre de dollar s, on va appeler cette lettre "dollar value"
Un foreach est une boucle qui étudie chaque cas d'un tableau
Un split est la transformation d'un texte en un tableau qui contient chacune de ses lettres, par exemple "bonjour" deviens le tableau [ "b" , "o" , "n" , "j" , "o" , "u" , "r"]
J'utilisai la même technique utilisée précédemment : un foreach combiné à un split permet de d'étudier chaque lettre d'un texte
J'ai l'habitude d'appeler chaque élément d'un foreach directement "$value" car c'est ce que mon éditeur de code propose par défaut, ainsi je ne me casse pas la tête.
if( in_array($value, $arr_chara_kebab))En français : si la lettre dans "dollar value" est dans le tableau qui contient chaque lettre autorisée dans l'écriture en kébab... alors...
$s_tmp .= $value ;En français : ...j'ajoute la lettre dans la boîte
Ici l'opérateur .= est un raccourcie pour signifie "je rajoute à la fin du texte", donc on y rajoute dollar value, notre lettre en question.
Écriture verticale
foreach (mb_str_split($s) as $value) {
if( in_array($value, $arr_chara_kebab)) {
$s_tmp .= $value ;
}
}
Si une boucle ou une condition ne contient qu'une seule instruction, on peux se permettre l'écriture horizontale, je la recommande pas aux débutants, et pour l'utiliser correctement, il faut la lire naturellement en anglais.
foreach (mb_str_split($s) as $value) if( in_array($value, $arr_chara_kebab)) $s_tmp .= $value ;
En français : Pour chaque lettre, si elle est autorisée dans l'écriture en kébab, alors je la rajoute dans "dollar s underscore value".
APRÈS
$s = $s_tmp;En français : dollar s devient égale à $s_tmp
Je rappelle que $s est le texte qu'on transforme depuis le début, le "héros du jour", et $s_tmp était une variable temporelle que j'avais utilisée pour mon avant-pendant-après
Tout le code pour n'autoriser que les caractères de kébab
$chara_kebab = '-0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' ;
$arr_chara_kebab = str_split($chara_kebab);
$s_tmp = '';
foreach (mb_str_split($s) as $value) if( in_array($value, $arr_chara_kebab)) $s_tmp .= $value ;
$s = $s_tmp;
Je tiens à préciser que la raison d'être de la variable $arr_chara_kebab est d'utiliser une boucle paresseuse, c'est-à-dire à l'intérieur de la boucle, je ne vais pas redéfinir la même variable, faire les même calculs, ça sert à rien et c'est du gaspillage de temps, alors je crée les variables et je prépare les calculs AVANT une boucle pour les utiliser à l'intérieur.
On enlève les traits d'union du début et de la fin
$s = trim($s,'-');En général, un trim consiste à enlever tous les espaces avant et après un texte. ça se traduit par "tailler, rogner".
PHP, contrairement à JavaScript, a le pouvoir de prendre un paramètre dans son trim, ainsi au lieu de se contenter d'enlever les espaces, on peux enlever d'autres caractères. Ici je décide d'enlever les traits d'union avec trim($s, '-')
while(strpos($s, '--')!==false)
La boucle while se traduit par "tant que"
strpos($s, '--')!==false se traduit par "si $s contient --"
PHP pendant longtemps n'a pas eu de fonction "est-ce que ce texte contient ça ?", on devait bricoler avec le morceau de code là.
À présent la fonction str_contains permet cela Pourquoi je ne l'utilise pas ? Car ça date de PHP 8, et il ne faut pas utiliser des fonctions trop récentes dans son code, sinon une fois mises en ligne, elles peuvent avoir des problèmes car les serveurs se méfient de ce qui est trop nouveau et ont toujours - par prudence - un petit temps de retard. Ainsi les codes trop récents n'y fonctionnent pas.
Pour les personnes curieuses, je vais détailler strpos($s, '--')!==false.
On cherche la position de la première occurrence de deux traits d'union consécutifs, '--', à l'intérieur de notre texte $s, si la fonction n'en trouve aucune, alors elle affichera false. Ici on veux faire la boucle si justement c'est l'inverse, s'il en trouve, car ce qu'il y a l'intérieur de la boucle est ce qui résout un problème, ainsi l'opérateur !== signifie "différent" de false ?
$s = str_ireplace('--', '-',$s); Donc tant que je trouve deux traits d'union côté à côté, je remplace -- par -, ça me permet ainsi d'enlever tous les doubles.
Note : si je n'utiliserai pas de boucle, j'enlèverai que les doublons --, mais les autres répétitions tel que ------- ne seraient pas réduit..., d'où l'utilité du while.
Ainsi personnellement j'utilise l'écriture horizontale :
while(strpos($s, '--')!==false) $s = str_ireplace('--', '-',$s);À la fin on dit à la fonction de retourner le résultat
return $s;Finitions
Même si le code est interprété du haut vers le bas et de la gauche vers la droite, le développeur ne l'écrit pas forcément dans cet ordre là.
Ainsi je rajouterai cette ligne au tout début :
$s = trim(html_entity_decode($s));Il permet de faire un premier trim (c'est-à-dire enlever les espaces avant et après le texte).
Et la fonction html_entity_decode permet de transformer les entité html en caractère, par exemple en html, si j'écris €, ça m'écrit directement le signe €, et dans ce cas je décide ainsi de d'abord obtenir mes caractères traduits
€se traduit en kebab pareur€se traduit en kebab par-euro-
Bon ce n'est pas si gênant que ça pour cet exemple, mais ça peux l'être plus pour d'autres nombreux symboles tel que < > © & etc.
Code complet
<?php
function kebab(string $s){
$s = trim(html_entity_decode($s));//ligne rajoutée à la fin
// caratères à remplacer par d'autres caratères
// voyelles
$s = str_ireplace(mb_str_split('áâàåãä'), 'a',$s);
$s = str_ireplace(mb_str_split('æ'), 'ae',$s);
$s = str_ireplace(mb_str_split('éêèë'), 'e',$s);
$s = str_ireplace(mb_str_split('íîìï'), 'i',$s);
$s = str_ireplace(mb_str_split('óôòøõö'), 'o',$s);
$s = str_ireplace(mb_str_split('œ'), 'oe',$s);
$s = str_ireplace(mb_str_split('ùûüúûùü'), 'u',$s);
$s = str_ireplace(mb_str_split('ýÿ'), 'y',$s);
// consonnes
$s = str_ireplace(mb_str_split('ç¢'), 'c',$s);
$s = str_ireplace(mb_str_split('Ð'), 'd',$s);
$s = str_ireplace(mb_str_split('ñ'), 'n',$s);
$s = str_ireplace(mb_str_split('š'), 's',$s);
$s = str_ireplace(mb_str_split('€'), 'e',$s);
// autres
$s = str_ireplace(mb_str_split('ƒ'), 'f',$s);
$s = str_ireplace(mb_str_split('ß'), 'ss',$s);
$s = str_ireplace(mb_str_split('$'), 'dol',$s);
$s = str_ireplace(mb_str_split('@'), 'at',$s);
$s = str_ireplace(mb_str_split('²'), '2',$s);
$s = str_ireplace(mb_str_split('³'), '3',$s);
// caractères à remplacer par un -
$s = str_ireplace(mb_str_split('&~"`°=¨£¤%µ,;:§_\''), '-',$s);
$s = str_ireplace(mb_str_split('^\\|.{}[]()?#!+*'), '-',$s); // regex sauf dollar // (laisser) }
$s = str_ireplace(mb_str_split(' '), '-',$s);//espace
// on enleve tous les autres caractères
// on ne trie plus que les caracteres autorisés en kebab, pour enlever les émoticônes qui font plusieurs bytes (certains se mélangent) ❤ est plus court que 🔁
$chara_kebab = '-0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' ;
$arr_chara_kebab = str_split($chara_kebab);
$s_tmp = '';
foreach (mb_str_split($s) as $value) if( in_array($value, $arr_chara_kebab)) $s_tmp .= $value ;
$s = $s_tmp;
//enlever les - au debut et a la fin
$s = trim($s,'-');
// on enlève les tirets en doublon
while(strpos($s, '--')!==false) $s = str_ireplace('--', '-',$s); // plusieurs tirets
return $s;
}
Ah les gens ! Je ne sais pas vous mais moi je suis crevé à la suite de cet article qui m'a demandé des heures d'écriture, c'est long un blog !!!
J'espère juste que ça sera utile à au moins une personne sur cette Terre...
Liste des fonctions natives utilisées dans cette page
Si vous êtes travailleur, n'hésitez pas à les noter quelque part et écrire la briève définition que la documentation donne en début de page.
- strtolower
- mb_strtolower
- str_ireplace
- str_replace
- mb_str_split
- str_split
- in_array
- trim
- strpos
- str_contains
- html_entity_decode
💪💪💪💪💪💪 DÉFI 💪💪💪💪💪💪
Seriez-vous capable de coder ces autres manières d'écrire ? (ou du moins, auriez-vous l'intuition de savoir comment faire ?)
- Écriture en serpent :
bonjour_madame_michu - Écriture en serpent majuscule :
BONJOUR_MADAME_MICHU - Écriture en accolé:
bonjourmadamemichu
Ça tombe bien c'est le sujet du prochain article ! (la tête de certains : 😱 ) Spoiler : c'est facile en vérité, beaucoup plus digeste que cet article !
Merci d'avoir lu !
Si en général vous avez une question, une curiosité, n'hésitez pas me contacter.